Python GTK Spellcheck¶

Python GTK Spellcheck is a simple but quite powerful spellchecking library for GTK written in pure Python. It’s spellchecking component is based on Enchant and it supports both GTK 3 and 4 via PyGObject.
✨ Features¶
spellchecking based on Enchant for
GtkTextViewsupport for word, line, and multiline ignore regular expressions
support for both GTK 3 and 4 via PyGObject for Python 3
localized names of the available languages based on ISO-Codes
support for custom ignore tags and hot swap of
GtkTextBuffersupport for Hunspell (LibreOffice) and Aspell (GNU) dictionaries
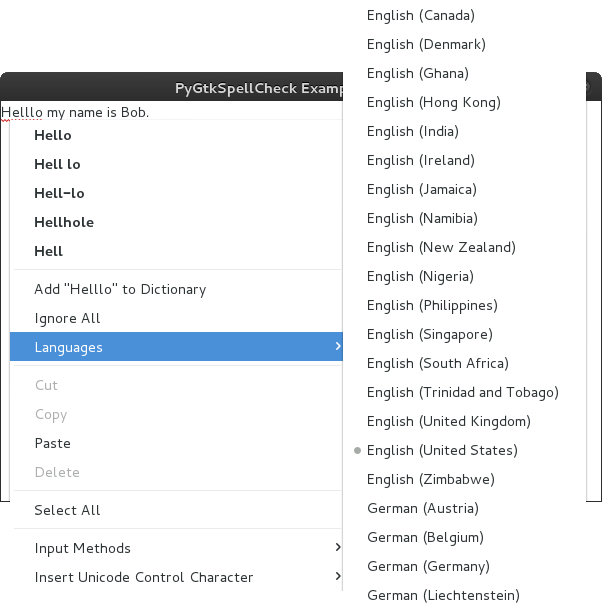
🚀 Getting Started¶
Python GTK Spellcheck is available from the Python Package Index:
pip install pygtkspellcheck
Depending on your distribution, you may also find Python GTK Spellcheck in your package manager.
For instance, on Debian you may want to install the python3-gtkspellcheck package.
📚 Documentation¶
Automatic GTK Version Detection¶
Python GTK Spellcheck will automatically detect the version of GTK (3 or 4) used by your project. To this end, you have to import GTK before importing gtkspellcheck. For example:
import gi
gi.require_version("Gtk", "4.0")
from gi.repository import Gtk
from gtkspellcheck import SpellChecker
Python GTK Spellcheck will configure itself to use GTK 4 for the example above.
API Reference¶
- class gtkspellcheck.spellcheck.SpellChecker(view, language='en', prefix='gtkspellchecker', collapse=True, params=None)¶
Main spellchecking class, everything important happens here.
- Parameters
view – GtkTextView the SpellChecker should be attached to.
language – The language which should be used for spellchecking. Use a combination of two letter lower-case ISO 639 language code with a two letter upper-case ISO 3166 country code, for example en_US or de_DE.
prefix – A prefix for some internal GtkTextMarks.
collapse – Enclose suggestions in its own menu.
params – Dictionary with Enchant broker parameters that should be set e.g. enchant.myspell.dictionary.path.
- languages¶
A list of supported languages.
- exists(language)¶
Checks if a language exists.
- Parameters
language – language to check
- add_to_dictionary(word)¶
Adds a word to user’s dictionary.
- Parameters
word – The word to add.
- append_filter(regex, filter_type)¶
Append a new filter to the filter list. Filters are useful to ignore some misspelled words based on regular expressions.
- Parameters
regex – The regex used for filtering.
filter_type – The type of the filter.
Filter Types:
SpellChecker.FILTER_WORD: The regex must match the whole wordyou want to filter. The word separation is done by Pango’s word separation algorithm so, for example, urls won’t work here because they are split in many words.
SpellChecker.FILTER_LINE: If the expression you want to matchis a single line expression use this type. It should not be an open end expression because then the rest of the line with the text you want to filter will become correct.
SpellChecker.FILTER_TEXT: Use this if you want to filtermultiline expressions. The regex will be compiled with the re.MULTILINE flag. Same with open end expressions apply here.
- append_ignore_tag(tag)¶
Appends a tag to the list of ignored tags. A string will be automatic resolved into a tag object.
- Parameters
tag – Tag object or tag name.
- batched_rechecking¶
Whether to enable batched rechecking of large buffers.
- buffer_initialize()¶
Initialize the GtkTextBuffer associated with the GtkTextView. If you have associated a new GtkTextBuffer with the GtkTextView call this method.
- check_range(start, end, force_all=False)¶
Checks a specified range between two GtkTextIters.
- Parameters
start – Start iter - checking starts here.
end – End iter - checking ends here.
- disable()¶
Disable spellchecking.
- enable()¶
Enable spellchecking.
- enabled¶
Enable or disable spellchecking.
- extra_chars¶
Fetch the list of extra characters beyond which words are extended.
- ignore_all(word)¶
Ignores a word for the current session.
- Parameters
word – The word to ignore.
- language¶
The language used for spellchecking.
- move_click_mark(iter)¶
Move the “click” mark, used to determine the word being checked.
- Parameters
iter – TextIter for the new location
Populate the provided menu with spelling items.
- Parameters
menu – The menu to populate.
- recheck()¶
Rechecks the spelling of the whole text.
- remove_filter(regex, filter_type)¶
Remove a filter from the filter list.
- Parameters
regex – The regex which used for filtering.
filter_type – The type of the filter.
- remove_ignore_tag(tag)¶
Removes a tag from the list of ignored tags. A string will be automatic resolved into a tag object.
- Parameters
tag – Tag object or tag name.
- class gtkspellcheck.spellcheck.NoDictionariesFound¶
There aren’t any dictionaries installed on the current system so spellchecking could not work in any way.
Examples¶
We also have examples demonstrating various configurations and and how Python GTK Spellcheck can be used.
🥳 Showcase¶
Over time, several projects have used Python GTK Spellcheck or are still using it. Among those are:
Nested Editor: “Specialized editor for structured documents.”
Cherry Tree: “A hierarchical note taking application, […].”
Zim: “Zim is a graphical text editor used to maintain a collection of wiki pages.”
REMARKABLE: “The best markdown editor for Linux and Windows.”
RedNotebook: “RedNotebook is a modern journal.”
Reportbug: “Reports bugs in the Debian distribution.”
UberWriter: “UberWriter is a writing application for markdown.”
Gourmet: “Gourmet Recipe Manager is a manager, editor, and organizer for recipes.“
🔖 Versions¶
Version numbers follow Semantic Versioning. However, the version change from 3 to 4 pertains only API incompatible changes in oxt_extract and not the spellchecking component. The update from 4 to 5 removed support for Python 2, GTK 2, pylocales, and the oxt_extract API.
🏗 Contributing¶
We welcome all kinds of contributions! ❤️
For details, checkout our GitHub Repository.